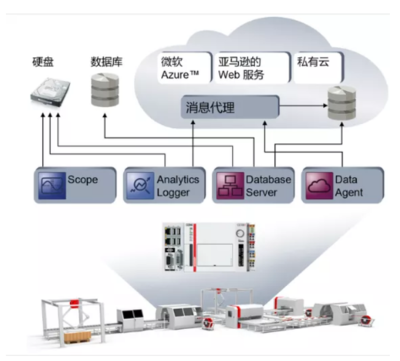
隨著數(shù)據(jù)量的爆炸式增長和業(yè)務(wù)復雜性的提升,將機器學習(ML)引入自動化流程已成為企業(yè)提升效率與決策智能的關(guān)鍵。尤其在數(shù)據(jù)庫服務(wù)領(lǐng)域,機器學習能夠從海量數(shù)據(jù)中挖掘隱藏模式,實現(xiàn)預(yù)測性維護、智能優(yōu)化和自動化決策。本文將揭示如何僅用三步,借助數(shù)據(jù)庫服務(wù)輕松實現(xiàn)機器學習的自動化集成。
第一步:數(shù)據(jù)準備與集成——構(gòu)建智能化的數(shù)據(jù)基礎(chǔ)
機器學習的核心在于數(shù)據(jù)。需要確保數(shù)據(jù)庫服務(wù)能夠高效地收集、存儲和管理結(jié)構(gòu)化和非結(jié)構(gòu)化數(shù)據(jù)。現(xiàn)代云數(shù)據(jù)庫(如Amazon RDS、Google Cloud SQL或Azure SQL Database)通常內(nèi)置了數(shù)據(jù)管道工具,支持實時數(shù)據(jù)流接入。通過ETL(提取、轉(zhuǎn)換、加載)流程,將業(yè)務(wù)數(shù)據(jù)清洗并整合到統(tǒng)一的數(shù)據(jù)倉庫或數(shù)據(jù)湖中,為機器學習模型提供高質(zhì)量的訓練數(shù)據(jù)集。例如,可以利用數(shù)據(jù)庫的自動化備份和快照功能,定期創(chuàng)建數(shù)據(jù)副本用于模型訓練,同時確保數(shù)據(jù)安全與一致性。
第二步:模型開發(fā)與部署——在數(shù)據(jù)庫環(huán)境中嵌入機器學習能力
傳統(tǒng)上,機器學習模型開發(fā)需要獨立的數(shù)據(jù)科學平臺,但現(xiàn)在許多數(shù)據(jù)庫服務(wù)已集成ML功能。例如,Google BigQuery ML允許用戶直接使用SQL語句構(gòu)建和訓練模型,無需將數(shù)據(jù)導出到外部系統(tǒng)。這一步包括:選擇適合自動化任務(wù)的算法(如分類、回歸或聚類),在數(shù)據(jù)庫內(nèi)進行模型訓練和驗證,然后通過API或內(nèi)置函數(shù)將模型部署為數(shù)據(jù)庫服務(wù)的一部分。自動化流程可設(shè)置為定時觸發(fā)模型重新訓練,以適配數(shù)據(jù)變化。利用數(shù)據(jù)庫的存儲過程和觸發(fā)器,可以自動調(diào)用模型對新數(shù)據(jù)進行預(yù)測,實現(xiàn)實時智能響應(yīng)。
第三步:自動化工作流與監(jiān)控——實現(xiàn)端到端的智能運維
將訓練好的模型融入自動化工作流是最后一步。通過數(shù)據(jù)庫服務(wù)的事件驅(qū)動架構(gòu)(如使用消息隊列或流處理服務(wù)),可以設(shè)置自動化規(guī)則:當數(shù)據(jù)達到特定閾值時,自動觸發(fā)模型預(yù)測并執(zhí)行相應(yīng)操作。例如,在電商數(shù)據(jù)庫中,機器學習模型可預(yù)測庫存需求,并自動觸發(fā)補貨訂單;在運維場景中,模型可檢測數(shù)據(jù)庫性能異常,并自動調(diào)整配置或發(fā)出警報。建立監(jiān)控機制跟蹤模型準確性和系統(tǒng)性能,利用數(shù)據(jù)庫日志和儀表板工具(如Grafana或Cloud Monitoring)實現(xiàn)可視化反饋,確保自動化流程持續(xù)優(yōu)化。
將機器學習引入自動化并非遙不可及。通過數(shù)據(jù)庫服務(wù)的現(xiàn)代化能力,企業(yè)只需遵循數(shù)據(jù)準備、模型內(nèi)嵌和工作流自動化這三步,即可構(gòu)建一個智能、自適應(yīng)的系統(tǒng)。這不僅降低了技術(shù)門檻,還加速了從數(shù)據(jù)到洞察的轉(zhuǎn)換,為業(yè)務(wù)創(chuàng)新提供強大動力。隨著AI與數(shù)據(jù)庫服務(wù)的進一步融合,自動化將變得更加智能和普及。